End-to-End Light-Weight Machine learning model deployment (Using Statistics, Python, Streamlit, Heroku, and Github)
Introduction
This article is based on a Python@Home challenge organized by Technidus. The challenge is based on a real-life Data Science challenge and follows an entire AI modeling workflow from the start to the end.
The Scenario :
A real estate property Aggregation company with Property Aggregation websites needs a rent budget estimator feature to be embedded. This estimator would help clients quickly estimate their rent budget based on house location, house size, estate or not an estate, bedrooms, toilets, etc.
For better reading and comprehension, this publication follows these outlines:
✅ Objectives
✅ Uniqueness of Projects
✅ Data Collection and Description
✅ Data Quality Check and Feature Engineering
✅ Data Modelling
✅ Light-weight Deployment with Heroku, Github, and Streamlit tools
Objectives
The following objectives are considered for the project
✅Web scraping of house rent Datasets from scratch using beautifulSoup module
✅Creating more features from the location description variable and logical, statistical conclusions from the test data price columns.
✅Building a model with an RMSE score of 80%.
✅Building an End-End Model Pipeline using Heroku, Github.
✅Presenting an ML model Rent Estimation APP with streamlit
Uniqueness of Project
The following are the uniqueness of the home challenge
✅ No dataset was given (not the regular Kaggle competition type)
✅ Creating new features using Statistical logical Conclusions.
✅ New features & Model development was impacted by factors such as
Inaccurate Property rent details given by the Estate agents. i.e., A house located in an estate is usually expensive, but some information for this was not recorded. Detached homes in an estate should be costly but low in some instances within the records posted.
✅ RMSE must be improved within the Constraint given above.
✅ Kaggle Competition platform was used to determine the model with the best RMSE score
✅ End-End Deployment of ML Model with Heroku, Github, and Streamlit.
Data Collection and Description
As outlined in the introduction, no initial train dataset was given for this challenge. Instead, the trained dataset used for the challenge was scraped from a property website named www.propertyNG.com, and features web scraped are bedrooms, toilets, parking lots, location description, and the target (price) for the following locations: Ikeja, Ogba, Iyana Ipaja, Surulere, gbagada, Yaba, Lekki, Ajah, and Ikorodu.
Table1 describes the initial features Scraped from the websites. Complete code for the Webscraped datasets using beautifulsoup and URL requests is shown below.
The web scraped data describes 5188 house rent information, broken into train and test datasets. The training dataset makes up eighty percent of the total 4000 observations and eight columns. On the other hand, the test data comprises only twenty percent (1188 observations) of the dataset and eight columns.
Note: To web scraped datasets from websites, knowledge of web scraping tools like python beautifulsoup & Scrapy module, HTML, CSS, and Requests is required. The following tutorial link introduces the web scraping of a website.
Data Quality Check & Feature Engineering
Information from the ww.propertyNG.com websites was self-reported by house agents, and the reports are subject to errors, bias, and missing information. This will harm our final models. For example, some of the houses were missing data in the location description columns, i.e., some Estate/Serviced houses are not indicated as Estate/Serviced in the descriptions column. But the histogram distribution of rent prices in some locations shows higher prices as outliers indicating that such houses are likely to be in an estate / Serviced but never reported in the description columns.

Therefore other important features denoting if a rented apartment is in an "estate or not" (estate/not estate), "serviced/not serviced apartment," "terraced/not terraced" were created by Feature Engineering Techniques on the Location Description column of the Scraped data. Finally, statistically logical conclusions were made to impute the actual values of the newly created features.
The feature engineering done based on logical, statistical conclusions made to create more features and eliminate outliers are as follows:
✅ Features such as "Estate/Not estate," Serviced/Not Serviced, terraced/Not terraced were extracted from the Location_Description columns of the dataset.
✅ To eliminate outliers in the price columns due to errors and missing information of house agents, the following logical conclusion was made
✅ Houses in an estate, serviced, new homes are generally expensive.
✅ The distribution of prices of features can be used to make logical conclusions about the minimum and maximum price values of specific areas. E.g., if one bed in a room, say gbagada is typically less than six hundred thousand naira, you can assume higher prices are likely to be in an estate. Also, as for outliers, if one bed in gbagada is typically less than One million naira from the distribution graph with just a very few higher than One million, you can peg those outliers at One million naira.
(Kindly remember to click on the Follow button on the top left hand of this article 🙏🏻)
Based on the above logical assertions, "The median/50th percentile price of those houses with missing information is identified, and any house above the median tag identified is logically considered an estate flagged as 1. Also, "House prices higher than 80th percentile are classified as Serviced" was given a flag equal to 1. The same technique was used to add flag values to new/luxury columns."

Data Modelling
For this challenge, a simple RandomForest Algorithm was used. A RandomForest algorithm is a supervised learning algorithm used for regression and classification problems. It builds decision trees on different split samples and takes their majority vote for classification and average in case of regression.
Interested in RandomForestregressor Read More in the following link
https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/
Since the target variable in this challenge was a continuous variable, A RandomForestRegressor algorithm was used to build the model with an R2 score as the evaluation metric. The RMSE score of the RandomForrestRegressor Algorithm was 0.83.
The model built was stored as a pickled file ready for light-weight deployment.
Insert the code for the model and pickled built.
To Improve the prediction score, various techniques could be used like the; Hyperparameter Tuning of the model, trying other regression models like XgbRegressor, Lgbregressor, Stacking of multiple models.
Light-weight Deployment with Heroku, Github, Streamlit tools
Data Scientists are always deficient in deploying models created into production and application. This is due to more required skills like Django, Flask, HTML, and CSS, to deploy a model.
Gladly, many methods are available to easily and quickly deploy Data science/ machine learning models. Models can now be deployed with a streamlit package on Heroku within minutes. Streamlit presents a straightforward way of building a simple machine learning app in the shortest possible time. To make an app with streamlit, it is expected that you have at least a basic understanding of Python programming, HTML, CSS, and Heroku.
Heroku is a platform as a service (PaaS) module that allows developers to build, run, and operate applications on the Heroku cloud. It's highly recommended for doing a small-scale project.
The following steps were taken to build the house rent web app.
A)Creating a Github Repo.
Create a GitHub repo and clone a copy to the local system of your project. Then push/store all required deployment files like Cleaned CSV files, Streamlit .py, pickled(pkl) model, Requirement.txt, Procfile, Setup. sh files
Follow these tutorials to learn how to clone and push files into a Github repo.
https://www.analyticsvidhya.com/blog/2020/05/git-github-essential-guide-beginners/
https://www.digitalocean.com/community/tutorials/fork-clone-make-changes-push-to-github
The required files are as follows
1.1 Create a streamlit App file
Creating a streamlit app .py file requires a streamlit package running. The following shows how to install the streamlit package and test it on your command prompt.


Having confirmed your installation was successfully done, create a .py file (housing2.py in my case) using your preferred IDE (I enjoy using Anaconda's Spider). Then push the housing2.py file to your Github cloned (local) folder on your local system. Next, import the relevant libraries, including the streamlit library. Meanwhile, you must have the pickled file created from your model also pushed into the cloned folder. For a more detailed, step to step guide on how to build a streamlit app from scratch, visit this website as follows:
The following codes are code written for the streamlit app py file.
1.2 The Pickled file
The pickled file is the final result of the model created using either the pickle or joblib package. This file must be pushed/stored in your Github cloned repo.
from sklearn.externals import joblib
joblib.dump(model1, 'modelrf.pkl')
modelza= joblib.load('modelrf.pkl')1.3 The Requirements.txt file
This file contains all the required libraries for the project to work.
The pipreqs module can automatically create a requirement.txt file. The following shows how to install and use the pipreps modules.
pip install pipreqspipreqs ./
Our requirement.txt file is now ready! It should look something like the following.
streamlit==0.58.0
matplotlib==3.1.3
joblib==0.14.1
numpy==1.18.1
pandas==1.0.1
scikit-learn==0.22.11.4 The ProcFile
The Procfile is used to execute the setup. sh and then call the streamlit App to run the application. Therefore, your Procfile should look something like the following.
web: sh setup.sh && streamlit run housing2.py1.5 The Setup. sh
The setup. sh, the file must create a streamlit folder with credentials. toml and a config. toml file as shown in the git code below;
mkdir -p ~/.streamlit/
echo
"\[server]\n\
headless = true\n\
port = $PORT\n\
enableCORS = false\n\
\n\
" > ~/.streamlit/config.tomlB)Deploying the Model on Heroku
The following process was used in deploying this project:
a) Ensure all relevant files required for your Heroku deployments project are pushed/ uploaded to your remote (Online) Github repo.
The following are the files pushed to the Github repo for deployment.

To deploy your model on Heroku
I. Create a Heroku account from the following websites
II. Select "Create New App" under the drop-down "New."

III) Enter the appropriate app/project name using the specified format (use lower case letters, numbers, and hyphens — not underscore). Your project will be deployed as name.herokuapp.com

IV.) Select the deploy tab and set the deployment method as "Github."
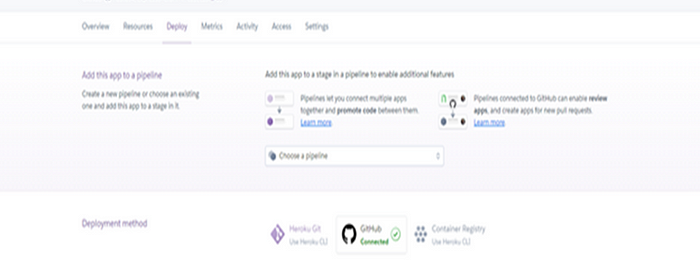
V.) Link your Github account with the created App on Heroku as shown below:
VI. Final End Product APP.
The final App can be viewed by clicking the following link :
https://ayanlola-app.herokuapp.com/

cRediT: Technidus Admins and Lekki data science meetup admin.
Thanks for Reading.
Did your Enjoy this Short-piece Kindly ♖ CLICK-ON the follow button at the top right corner to follow me for more Articles
